尚书六号汉字表格识别系统是一款图像文字识别软件,“尚书六号”可以对彩色、灰度图像文件直接进行识别,可以将图片中的文字读取并转换成可以编辑的文字显示出来。支持更多的扫描文件格式,例如tiff、bmp和jpg格式,与此同时,尚书六号完善了表格识别功能,各式各样的表格几乎都可以原封不动的由图片格式转变为可以自由编辑的文字格式。
尚书六号汉字表格识别系统特性
1、尚书六号支持TIFF、BMP和JPG格式等扫描。
2、OCR也就是文字识别技术,运用电脑或者扫描仪来识别图片或者数字图片文件里的文字内容,方便文字录入,提高工作效率。
3、支持彩色、灰度图像文件直接进行识别的OCR工具
4、使用只需要用本软件打开要识别的文字的图片,点击识别即可,识别率非常高,即便是有严重划痕和干扰的图片,也能达到惊人的98.5%!
尚书六号汉字表格识别系统使用教程
1. 扫描图像文件。
建议在桌面上直接使用SCANWIZARD 5软件,注意将软件切换到高级工作模式。原因是这样能便于用户检查扫描仪工作时的分辨率。
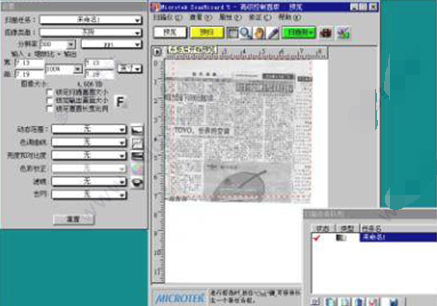
2.推荐的扫描分辨率设定在300DPI,色彩模式可以是“RGB彩色”或者“灰阶”。

3.选择“扫描到”的文件格式是TIF或者JPG两者都可以。将扫描的文件存在用户确定的目录下面。
4. 读取扫描好的图像文件,被识别图片的预处理。
这部分工作,主要包括:倾斜校正、设定正确的识别区域。
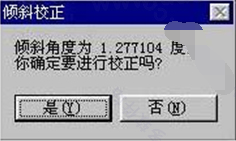
倾斜校正过程,按下“图像倾斜校正”工具,按下“是”按狃。系统就给予图片做水平的倾斜校正。
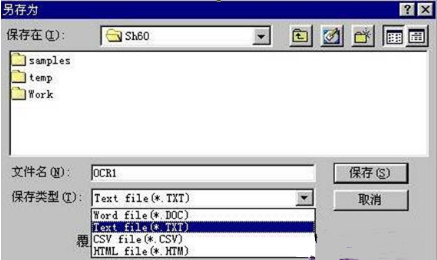
5. 识别校对完成后,存盘格式的选择文件保存的类型有四种,建议一般文本的识别,用户选择TXT格式。
如果是表格识别,识别结果请选择“CSV”格式,用EXCEL能够打开。