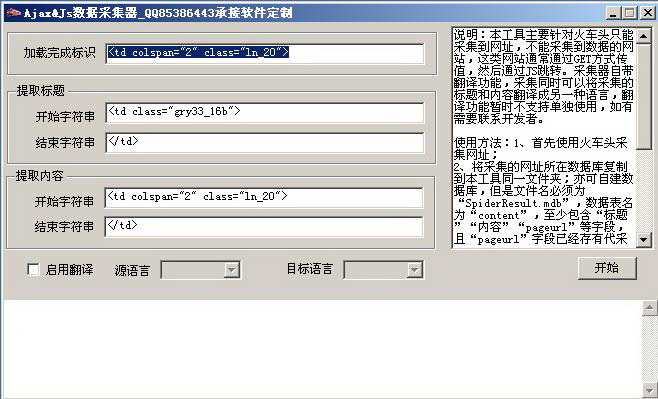




本工具主要针对火车头只能采集到网址,不能采集到数据的网站,这类网站通常通过GET方式传值,然后通过JS跳转。采集器自带翻译功能,采集同时可以将采集的标题和内容翻译成另一种语言,翻译功能暂时不支持单独使用,如有需要联系开发者。
使用方法:
1、首先使用火车头采集网址。
2、将采集的网址所在数据库复制到本工具同一文件夹;亦可自建数据库,但是文件名必须为“SpiderResult.mdb”,数据表名为“content”,至少包含“标题”“内容”“pageurl”等字段,且“pageurl”字段已经存有代采集网址。
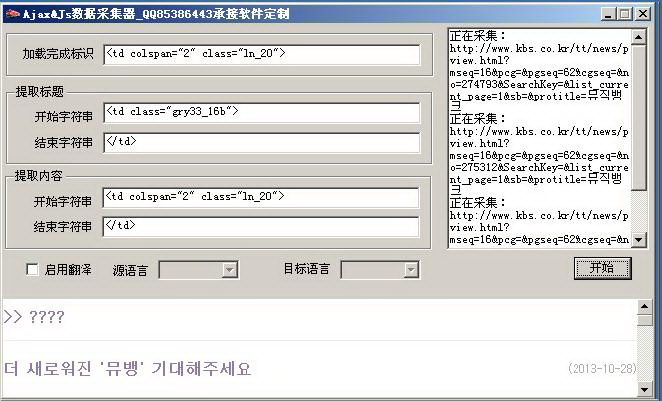
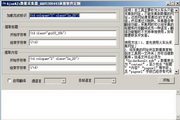
3、打开工具,依次填写网页加载完成的标识代码片段和提取标题内容的首尾代码片段,然后点击开始。
常见问题:
1、采集过程中自动中断,重启软件即可。
2、采集中弹出错误提示,打开数据库,删除当前采集的网址记录或将其标题和内容字段置为“F”然后重启软件。
3、其他,请联系开发者。