清华紫光OCR文字识别软件是由清华大学研发的专业图像汉字识别工具,支持印刷体与多种字体的高精度转换。用户可通过扫描仪或导入图像文件,快速识别并输出可编辑文本,支持多种主流文档格式导出。该软件广泛应用于文档电子化、图书录入、资料归档等场景,显著提升文字处理效率。喜欢清华紫光ocr文字识别软件的朋友快来华军软件宝库下载体验吧!
清华紫光ocr文字识别软件亮点
办公场景:
将纸质合同、报告、发票等快速转换为可编辑的电子文档,减少手动录入工作量。
支持表格识别,便于处理财务数据、统计报表等结构化信息。
学术场景:
识别书籍、论文中的文字和图表,支持学术资料整理与引用。
混排识别功能满足中英文文献的数字化需求。
档案管理:
批量数字化历史纸质档案,创建可搜索的电子库,便于长期保存与检索。
支持多语言文档处理,适应国际化档案管理需求。
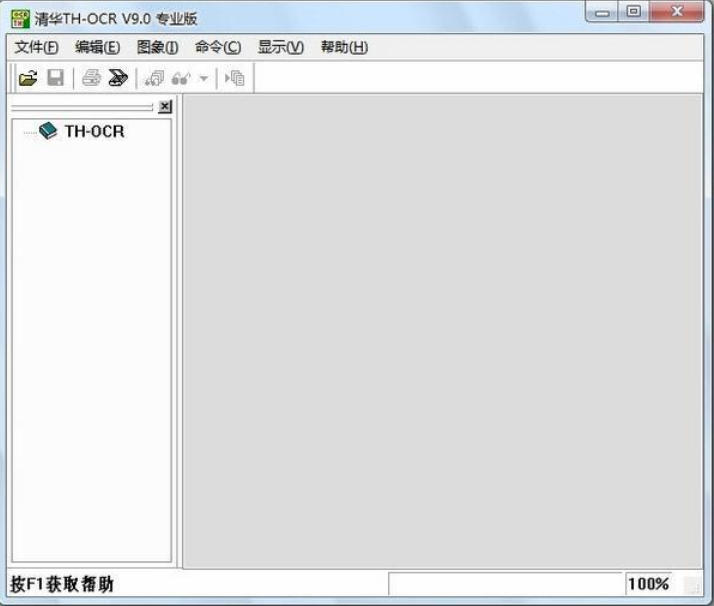
清华紫光ocr文字识别软件功能
高精度识别:
印刷体识别:采用先进的图像处理和模式识别算法,识别率超过99.5%(经“863”智能专家组评测),对标准印刷体汉字识别效果极佳。
手写体识别:支持手写中文和英文的识别,但需书写规范(如字迹清晰、无连笔、间隔合理),适合数字化手写笔记或信件。
表格识别:
自动识别表格框线并恢复文字到原表格结构,支持导出为RTF格式,便于在Word等软件中编辑。
批量处理:
支持批量识别多页文档,最多可处理10000页,避免重复操作,大幅提升处理效率。
多语言支持:
支持简/繁体中文、英文、日文、韩文等多种语言,以及中日韩文与英文混排文档的识别,识别水平超过国外同行。
格式兼容:
支持从TIF、BMP、PCX、JPG等常见图片格式中读取文字内容,并可将扫描图像转换为TIFF、BMP、PCZ等格式,灵活性高。
清华紫光ocr文字识别软件特色
MMX优化技术:
针对支持MMX指令集的处理器,印刷体识别速度提升约30%。
版面自动分析:
智能划分图文混排文档中的文字区域,确保高识别率的同时保持原始布局。
自学习功能:
遇到生僻字时,用户可通过键盘输入纠正,软件会学习并扩展识别字符集,提高长期使用准确性。
清华紫光ocr文字识别软件常见问题
表格识别问题:
在使用清华紫光OCR进行表格识别时,可能只能识别出表头而无法识别整个表格。这是因为软件可能无法自动对表格进行划分。解决方法包括手动版面划分,单独定义表格属性,将表头框为“横排正文”,将表格框为“表格”。
图像质量影响识别:
图像质量对识别效果有直接影响。如果图像模糊、噪声过多或倾斜,可能导致识别准确率下降。建议在扫描或拍摄时,确保图像清晰、无噪声,并校正倾斜。
清华紫光ocr文字识别软件更新日志:
1.优化内容
2.细节更出众,bug去无踪
华军小编推荐:
清华紫光ocr文字识别软件一直以来都是大多数网民最常用的软件,{zhandian}还有{recommendWords}等同样是网民非常喜爱的软件,大家可以来{zhandian}下载!